Throughout this site, in editorial content and on our award-winning Gold reports and racecards, there are references to various measures of performance or utility: horse racing metrics. Although some of the concepts may be new, their application – and therefore your understanding of them – is generally straightforward.
This article offers a brief run down of the metrics used, notably Impact Value (IV), Actual vs Expected (A/E) and Percentage of Rivals Beaten (PRB). In the following, I explain how the metrics are arrived at; but if you’re not a geeky type, simply make a note of the ‘what to look for’ component for each one.
Impact Value (IV)
IV helps to understand how often something happens in a specific situation by comparing it against a more general set of information for the same situation.
For example, we can get the IV of a trainer’s strike rate by comparing it with the average strike rate for all trainers.
Let’s say a trainer saddled 36 winners from 126 runners, a strike rate of 28.57%, during the National Hunt season.
And let's further say that, overall in that season, there were 3118 winners from 26441 runners. That’s an average strike rate of 11.79%.
We could simply divide the two strike rates:

28.57 / 11.79 = 2.42
Or we could do the long version, which at least helps understand the calculation. It goes like this:
('Thing' winners / All winners) / ('Thing' runners / All runners)
In this case,
(36 / 3118) / (126 / 26441)
= 0.011545 / 0.004765
= 2.42
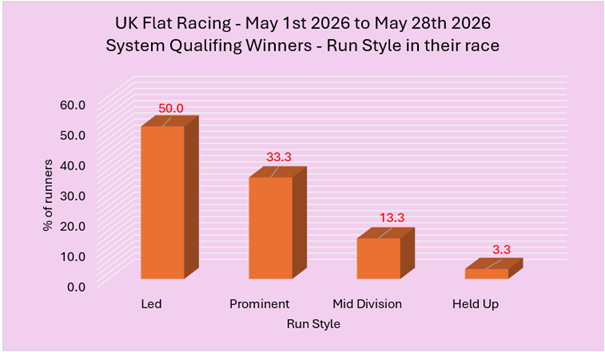
What to look for with IV
An IV of 1 is the 'standard' for the total rate of incidence of something. A number greater than 1 relates that something happens more than standard, and a number less than 1 implies it happens less than standard.
The further above or below 1 the IV figure is, the more or less frequently than ‘standard’ something happens.
The example IV of 2.42 means our trainer won at a rate nearly two-and-a-half times the overall trainer seasonal average: 2.42 times, to be precise.
Note that very small data samples can produce misleading IV figures.
IV3
IV3 is a derivation of IV created by us here at geegeez.co.uk to help ‘smooth the curve’ on chart data. You can see examples of this when looking at draw data on this website.
IV3 simply adds the IV of a piece of data to the IV's of its closest neighbouring pieces of data, and divides the sum by three.
For example, the IV3 figure for stall five at a racecourse would be calculated as:
(IVs4 + IVs5 + IVs6) / 3
where IVs4 is the Impact Value of stall 4, the lower neighbour of stall 5, whose IV3 we are calculating, and IVs6 is the Impact Value of stall 6, the upper neighbour of the stall whose IV3 we are calculating.
Thus, in the below example which shows stalls 1-5, the IV3 figure for stall 2 is the average of the IV figures for stalls 1, 2 and 3:
(1.98 + 2.27 + 2.55) / 3 = 2.27

As with IV, the greater the value the better, with anything above 1 representing an outcome which occurs more frequently than standard.
N.B. For the lowest and highest stalls in a race, IV3 is calculated from an average of the stall and its sole neighbour (stall 2 in the case of stall 1, and stall H-1 in the case of the (H)ighest numbered stall).
What to look for with IV3
Used on this site mainly in charts, IV3 shows a smoother, more representative curve when looking at the impact of stall position.
Example IV Chart:

Same data plotted by IV3:

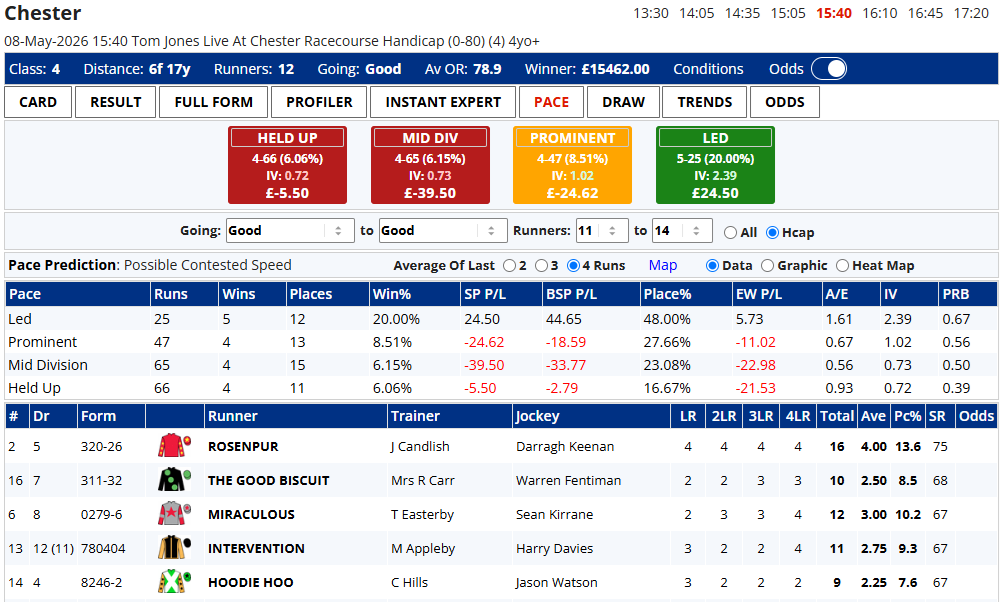
Actual vs Expected (A/E)
Whereas IV tells us how frequently, relatively, something happens, as bettors we need to know what the implied profitability of that something is. In concert, they are a powerful partnership, with favourable figures denoting an event that happens more frequently than average and with a positive betting expectation.
A/E, or the ratio of Actual versus Expected, attempts to establish the value proposition (profitability in simple terms) of a statistic. The 'actual' and 'expected' are the number of winners.
The ‘actual’ number of winners is just that. In the case of the IV example above, the trainer had 36 winners from 126 runners. Actual then is 36.
But how do we calculate the 'expected' number of winners?
We use a formula based on the starting price (you could just as easily use Betfair Starting Price or even tote return if you were sufficiently minded - we've used SP), thus:
Actual number of winners / Sum of ALL [entity] runners' SP's (in percentage terms)
So far we know that to be 36 / Sum of ALL [entity] runners' SP's (in percentage terms)
To establish a runner's SP in percentage terms, we do the sum 1/([SP as a decimal] + 1).
For instance, 4/1 SP would be 1/(4 + 1), or 1/5, which is 0.20,
evens SP would be 1/(1 + 1), or 1/2, which is 0.5,
1-4 SP would be 1/(0.25 + 1), or 1/1.25, which is 0.8, and so on.
The sum of our trainer's 126 runners' starting prices, calculated in the above fashion, is 33.15.
Our A/E then is 36 / 33.15 which is 1.09.
We can then say that this trainer’s horses have a slightly positive market expectation, and in general terms her horses look worth following.
What to look for with A/E
As with IV, a score above 1 is good and below 1 is not good, though in this case the degree of goodness or not goodness pertains to market expectation, or what might be summed up as ‘likelihood of future profitability’.
A dataset that shows a profit but has an A/E below 1 is probably as a result of one or two big outsiders winning. Such runners have a low expectation associated with them and are far less likely to represent winners in the future.
Clearly, then, we’re looking for an A/E above 1. But we need also to be apprehensive around ostensibly exciting profit figures when the A/E doesn’t back that up. That is, when the A/E figure is below 1.
Note also that very small data samples can produce misleading A/E figures.
Percentage of Rivals Beaten (PRB)
One of the main problems with assessing horseracing statistics is that we’re often faced with very small amounts of information from which to try to form a conclusion.
For this reason, I personally prefer place percentages to win percentages, as there are more place positions in a small group of races than there are winners. Thus, it tends to lead to slightly more representative findings.
PRB tries to take this race hierarchy a step further and produce a sliding scale of performance for every runner in a race based on where they finished.
So, for example, in a twelve-horse race, the winner beats 100% of its rivals, and the last placed horse beats 0% of its rivals. But what about those finishing between first and last?
The calculation is:
(runners - position) / (runners - 1)
The 4th placed horse's PRB in a 12-runner race would be calculated as:
(12 – 4) / (12 – 1)
= 8 / 11
= 0.73 (or 73%)
The full table of PRB’s for a 12-horse race is below.

A word on non-completions
There are different interpretations of how to cater for a horse which fails to complete (refused to race, unseated rider, fell, pulled up, etc).
Some exclude those runners from the calculation sample, others use a 50% of rivals beaten figure. The traditional way of dealing with non-completions - the way its creator, Simon Rowlands, has managed them since introducing %RB around 15 years ago - is to recode pulled ups as joint-last (so will be >0% if more than one), and fell etc as neutral (50% of rivals beaten).
Whilst I can see the rationale behind both of those, the approach we have taken is more literal: we assume a non-completing horse to have beaten 0% of its rivals. This is unfair on the leader who falls at the last but nor does it upgrade a tiring faller or a horse pulling up at the back of the field.
There is not really a perfect way to represent non-completions in PRB terms; this is at least a consistent interpretation which is of little consequence in larger datasets or where non-completions are rare (for example, in flat races).
What to look for with PRB
PRB is helpful when attempting to establish the merit of unplaced runs; for example, a horse finishing 5th of 24 in a big field handicap has fared a good bit better than a horse finishing 5th of 6.
A PRB figure of 55% or more can be considered a positive; by the same token, a PRB figure below 45% should be taken as a negative, all other things being equal.
The problem with PRB is that it assumes, as per the rules of racing, that every horse is ridden out to achieve its best possible placing. In reality that frequently fails to happen: horses whose chances have gone are eased off and allowed to come home in their own time.
Thus, the further from the winner you get, the less reliable is the PRB figure.
PRB2
As the name suggests, this is the PRB figure, expressed as a decimal, times itself. This is also sometimes written as PRB^2, which means the same as PRB2.

So, for example, if the percentage of rivals beaten was 80%, or 0.8, the PRB2 figure would be 0.8 x 0.8 = 0.64
The reason this is useful is that it rewards those finishing nearer to first exponentially, as the table and chart for an 11-runner race below illustrates.


The chart lines start and end in the same place but, in between, they are divergent.
The difference in the values is greater the further down the top half of the field a horse finishes, and then gravitates back towards the PRB line in the latter half of the field (where PRB2 scores are lowest).
This is significant when looking at, for example, trainer statistics. Let’s take an example where two trainers have the following finishes from three horses, all in eleven-runner races (for ease of calculation):

Using our reference table above for eleven-runner races, we could calculate the PRB’s, using decimals rather than fractions, as follows:
Trainer A: 1.0 + 0.5 + 0.0 = 1.5
Trainer B: 0.5 + 0.5 + 0.5 = 1.5
Both have a score of 1.5 which, when divided by the three runs, gives a PRB rating of 0.5.
But Trainer A had a winner and Trainer B failed to secure a finish better than 6th, so should we afford them the same merit?
Some will argue yes, but I prefer – and PRB^2 offers – to recognise all that has happened but to reward the trainer with the ‘meaningful’ placing to a greater degree than her perma-midfield counterpart.
Here’s how PRB^2 views the same trio of performances:
Trainer A: 1.0 + 0.25 + 0.00 = 1.25 / 3 = 0.42
Trainer B: 0.25 + 0.25 + 0.25 = 0.75 / 3 = 0.25
This time we see the preference towards Trainer A, who had the same average finishing position but the more worthy finish in that one of his runners won.
That, in my view, is a more meaningful statistic for all that it is not straightforward to know what a ‘good’ PRB^2 figure is.
What to look for with PRB^2
Anything above 0.4 on a reasonable sample size implies ‘good’ performance whereas anything below 0.3 on a reasonable sample implies ‘poor’ performance, though there is some scope for different interpretations between 0.3 and 0.4.
PRB3
PRB3, not to be confused with PRB^2, is used in the same way as IV3 when there is a logical and linear relationship between a data point and its closest neighbours. The example we used in IV3 was stall position and that holds equally for PRB3: it would be the average percentage of rivals beaten of a stall and its closest neighbours. Another example might be the rolling monthly percentage of rivals beaten for a trainer, although this will always be historical in its outlook (we cannot know next month's PRB).
As with IV3, its primary utility is one of smoothing the curve to make patterns in the data easier to spot.
Horse Racing Metrics Summary
Throughout the site, figures relating to Impact Value, Actual vs Expected, and Percentage of Rivals Beaten are referenced. There is nothing to be afraid of; rather, each metric simply provides an appropriate way of easily understanding the data (and, crucially, its utility), and comparing it within the context of the entity under investigation.
Other Recent Posts by This Author:
- Query Tool v2 is Finally Here (Very nearly!)
- Royal Ascot 2026: Day Four Preview, Trends, Tips
- Royal Ascot 2026: Day 3 Preview, Trends, Tips
- Royal Ascot 2026: Day 2 Preview, Trends, Tips
- Royal Ascot 2026: Day One Preview, Tips